
目前常用的Spark版本有三种Cloudera、HDP和Apache,源码的获取方式可以在各自官网下载。本文选择Apache版本。
搭建环境所需要的工具如下:
- CentOS 7
- maven 3.5.0
- Java 1.8.0
- Scala 2.12.2
- IntelliJ IDEA2017.1.2
本人选择在服务器上进行编译和调试,机器配置为至强CPU(56核)、内存256G。
下载源码
首先将 fork到自己的github仓库,接着再IDEA上通过VCS->Checkout from Version Control->Github 中选择刚刚fork下来到本地
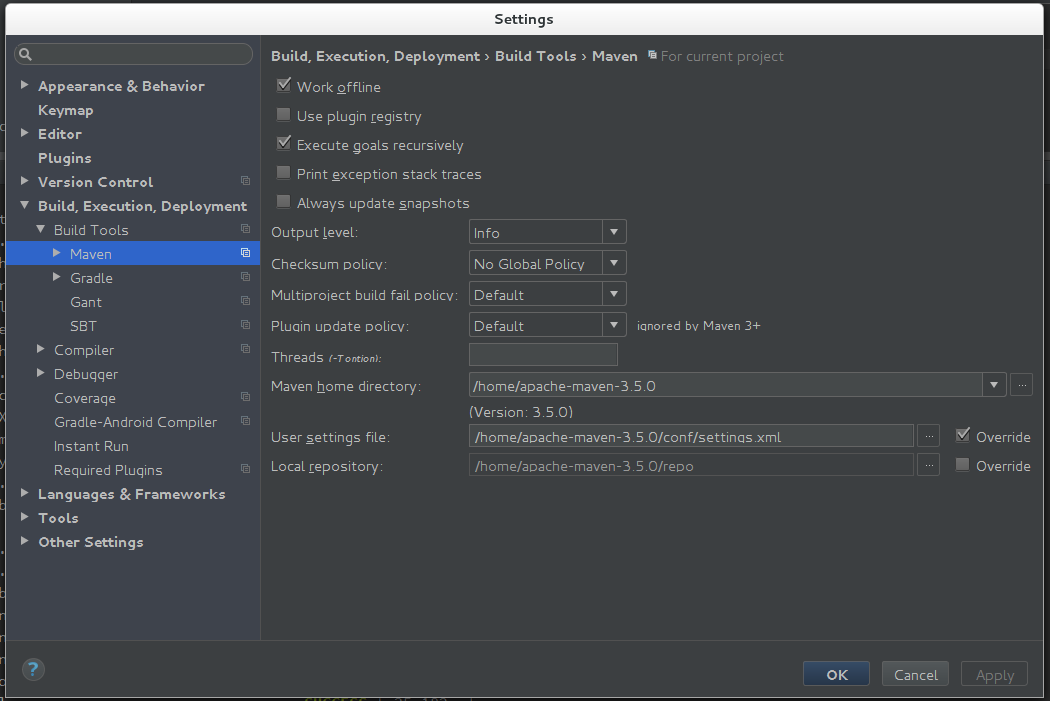
配置本地maven
本文选择使用自己搭建的maven仓库,Spark源码自带的maven会从官方镜像上下载所需的依赖,此步骤会比较耗时,设置为本地maven仓库后,速度会大幅提升。设置方法如下图所示
编译Spark源码
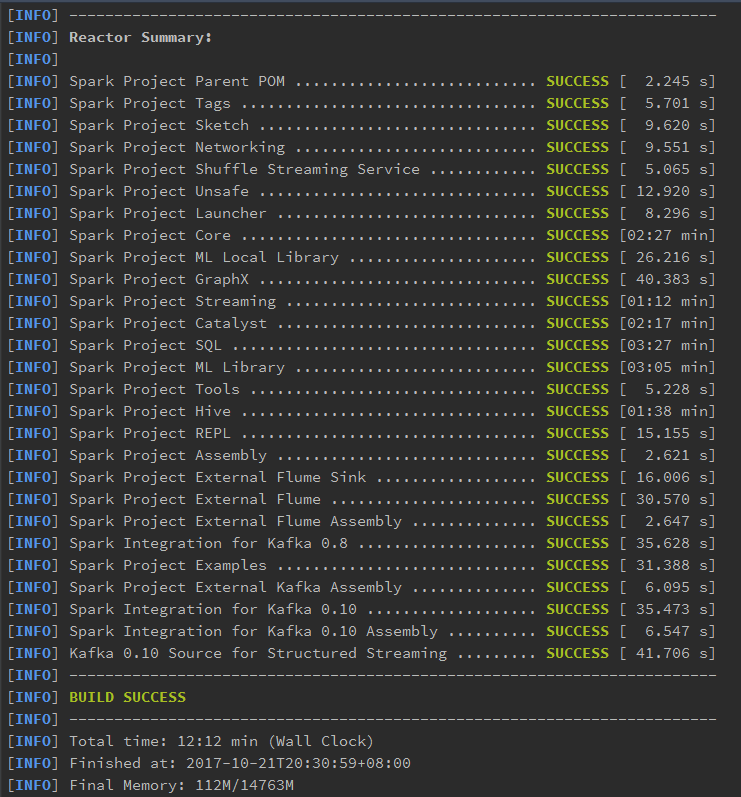
选择的最新版的Spark,目前是2.3.0。编译Spark源码,使用自己安装的maven进行编译,其中-T参数是设置编译的线程数,这里设置的是20
mvn -T 5 -DskipTests clean package
经过12分钟的等待,Spark源码编译完成,如下图所示
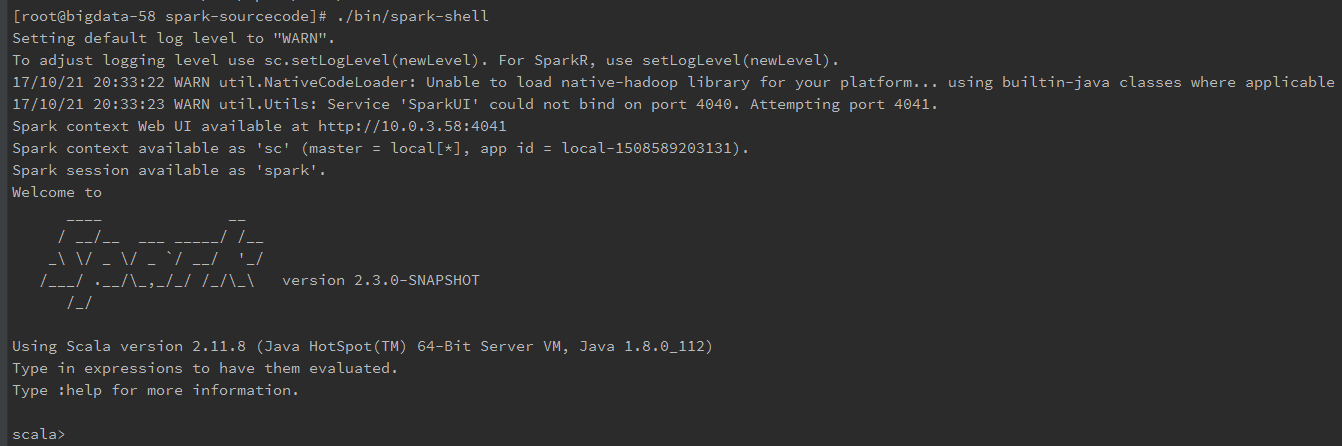
接着可以通过运行下spark-shell来测试一下编译结果
./bin/spark-shell
运行Spark源码自带的实例程序
由于大多数程序都是从hello world开始的,对应的,Spark的第一个程序为wordcount,我们选择调试JavaWordCount。
打开JavaWordCount程序
在代码编辑区右键选择
Create 'JavaWordCount.main()'...
设置如下图所示
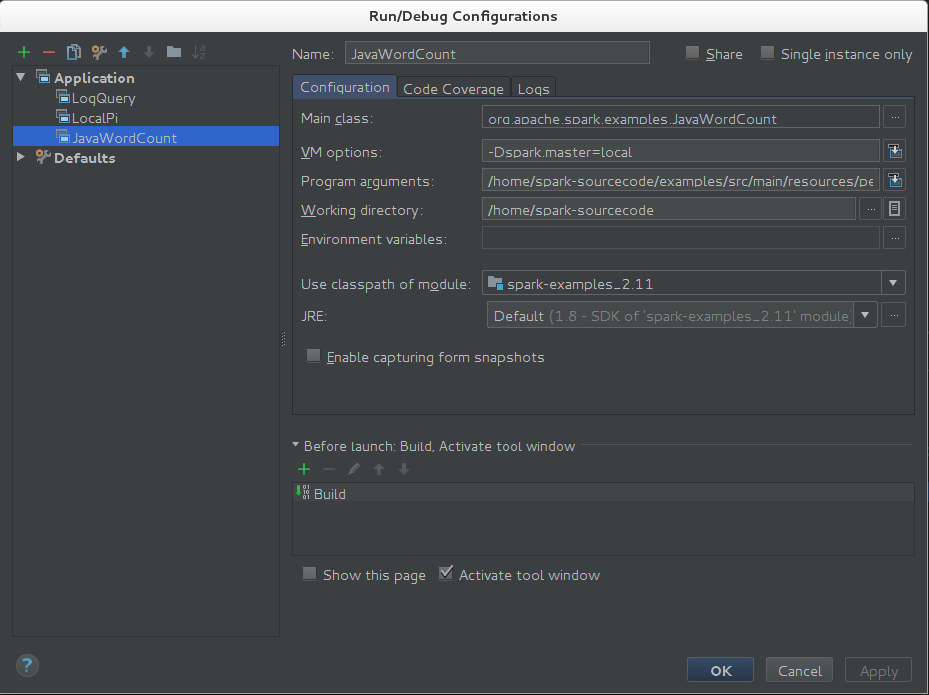
其中
VM options: -Dspark.master=local Program arguments:/home/spark-sourcecode/examples/src/main/resources/people.txt
保存运行配置,这样直接运行会出现以下两个错误,缺失flume sink
- 缺失flume sink

解决方法是在
View->Tool Windows->Maven Projects
在Spark Project External Flume Sink上右键选择Generate Sources and Update Folders
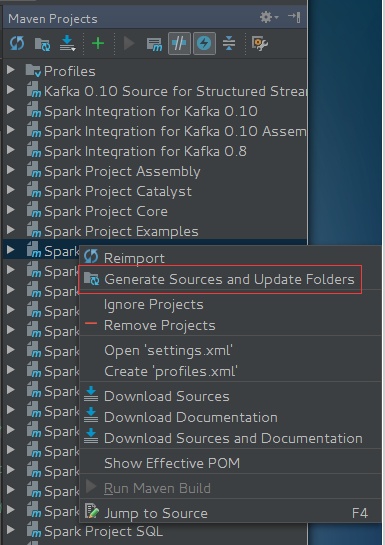
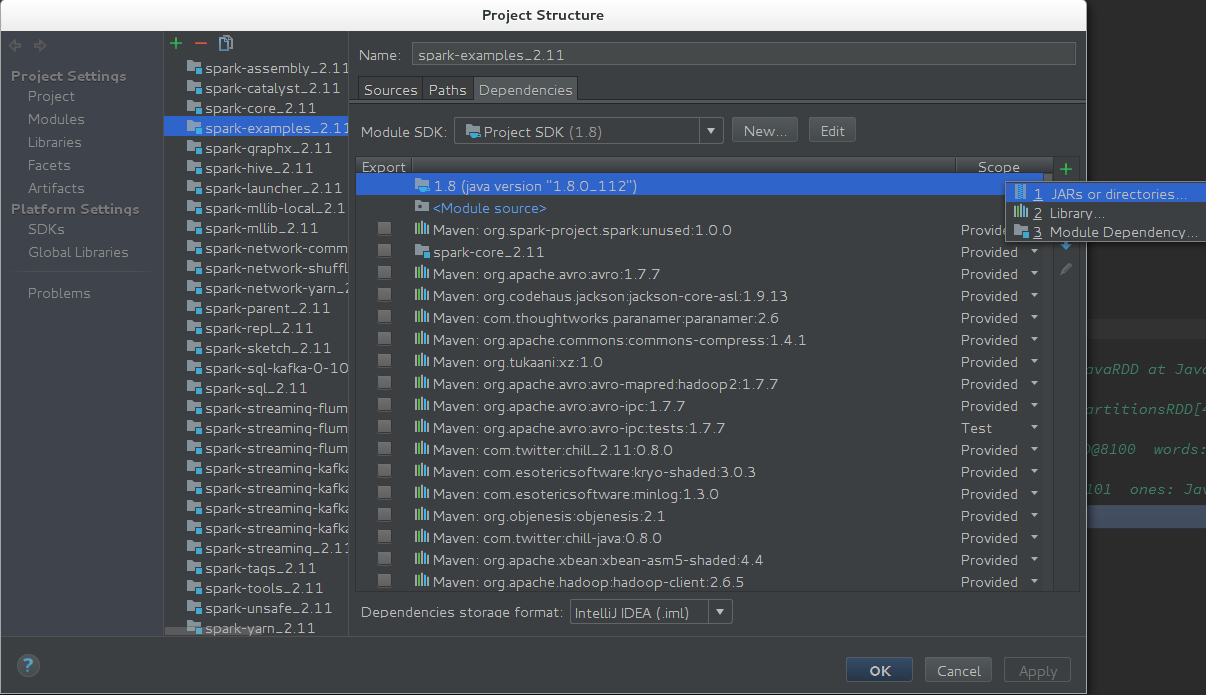
- 缺少Spark环境Jars包

解决方案如下:
File -> Project Structure -> Modules -> spark-examples_2.11 -> Dependencies 添加依赖 jars -> {spark dir}/spark/assembly/target/scala-2.11/jars/
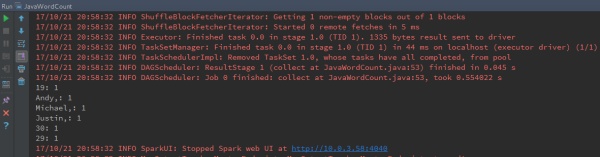
接着成功运行JavaWordCount
调试例子程序
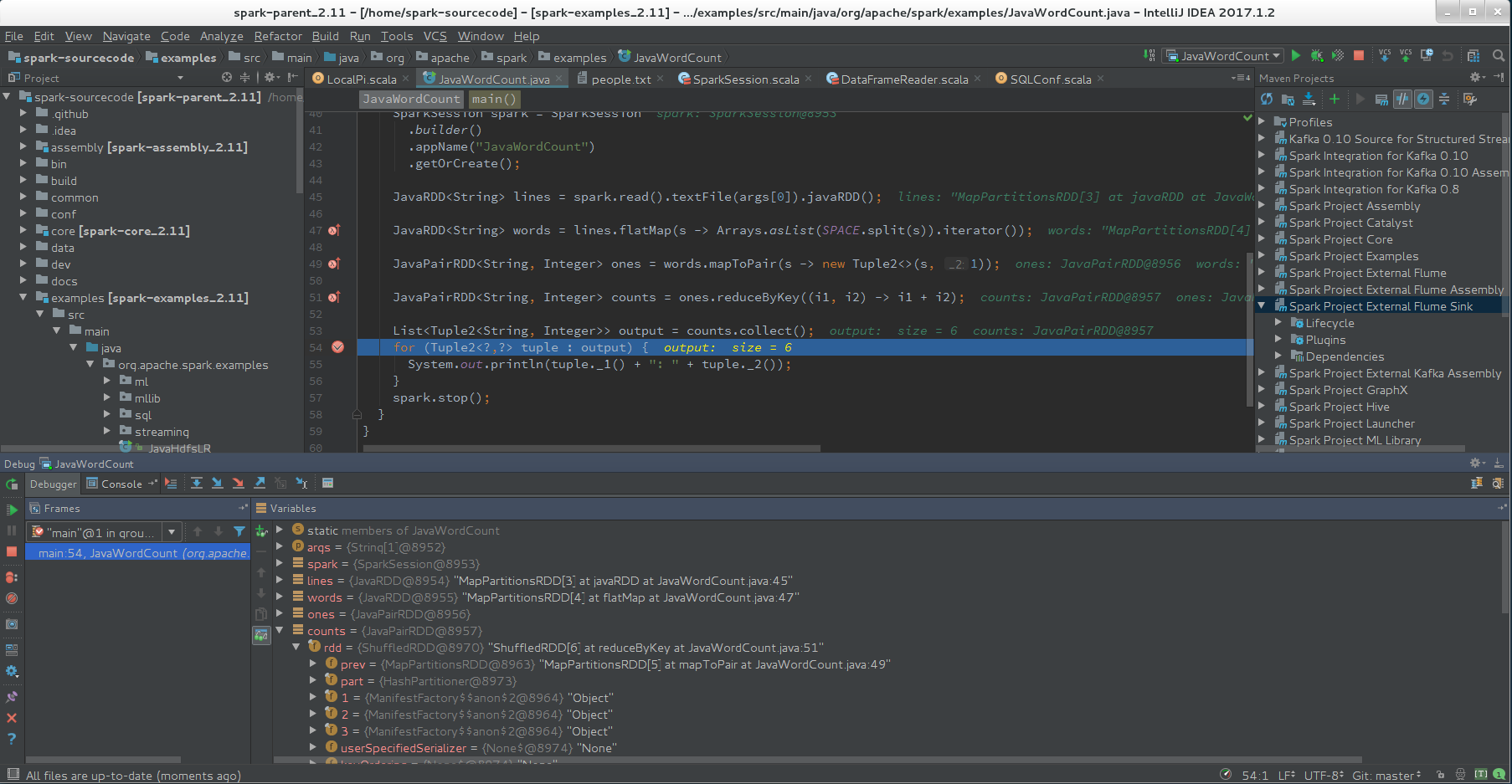
接下来就可以看到Spark程序运行时每个变量的值变化,方便我们对Spark源码的设计进行分析。
不过当我们修改了Spark源码后,我们得使用前面的编译命令对其进行重新编程生成。